JVM之内存结构
# 1 程序计数器
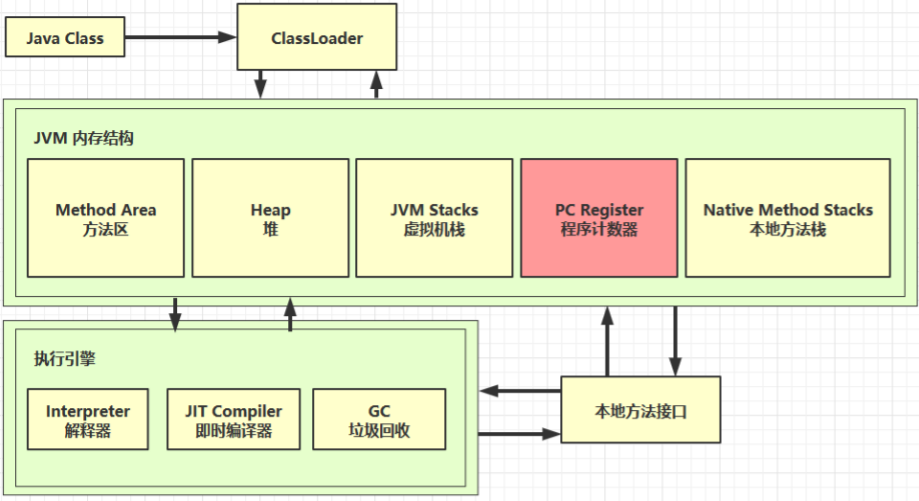
Program Counter Register 程序计数器(寄存器)
- 作用:是记住下一条jvm指令的执行地址
- 特点
- 是线程私有的
- 不会存在内存溢出
# 2 虚拟机栈
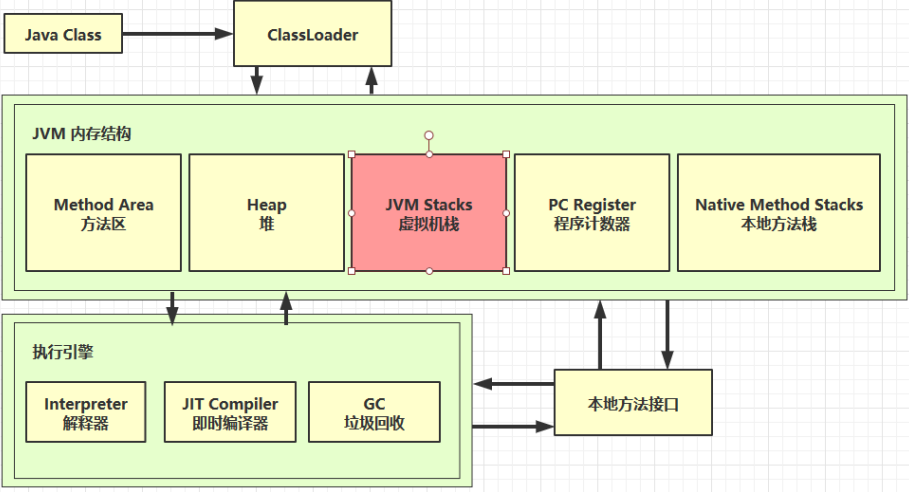
# 2.1 定义
Java Virtual Machine Stacks (Java 虚拟机栈)
- 每个线程运行时所需要的内存,称为虚拟机栈
- 每个栈由多个栈帧(Frame)组成,对应着每次方法调用时所占用的内存
- 每个线程只能有一个活动栈帧,对应着当前正在执行的那个方法
问题辨析
- 垃圾回收是否涉及栈内存?
- 每一个栈帧使用完后会自动释放该栈帧所对应的内存,垃圾回收只涉及到堆内存
- 栈内存分配越大越好吗?
- 每个线程都会对应一个栈内存,如果栈内存分配越大则所能使用的线程数则减小,也对程序的执行起不到加快的作用
- 方法内的局部变量是否线程安全?
- 如果方法内局部变量没有逃离方法的作用访问,它是线程安全的
- 如果是局部变量引用了对象,并逃离方法的作用范围,需要考虑线程安全
# 2.2 栈内存溢出
栈帧过多导致栈内存溢出
- 递归没有给到合适的出口
- 第三方组件使用不当导致循环引用(ObjectMapper:对象 -> Json)
栈帧过大导致栈内存溢出(局部变量过多导致,但较难触发)
Tip:
可以使用
-Xss来改变栈内存的大小栈内存溢出的错误信息为:
java.lang.StackOverflowError
# 2.3 线程运行诊断
eg1:CPU占用过多
定位问题步骤(Linux)
- 用
top命令定位哪个进程对CPU的占用过高 ps H -eo pid,tid,%cpu | grep 进程id(用ps命令进一步定义是哪个线程引起的cpu占用过高)jstack 进程id(可以根据线程id找到有问题的线程,进一步定位到问题代码的源码行号)
eg2:程序运行很长时间没有结果(线程死锁)
# 3 本地方法栈
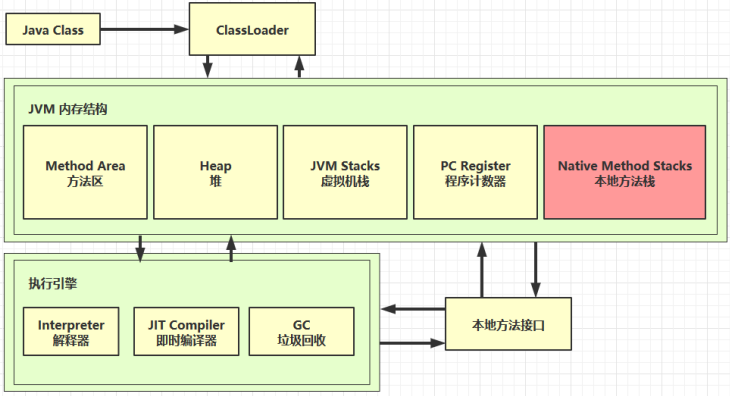
本地方法栈的作用类似于JVM虚拟机栈,就是调用本地方法Native时会开辟一个本地方法的执行内存,也就是本地方法栈,其中有调用库函数的执行栈帧。
# 4 堆
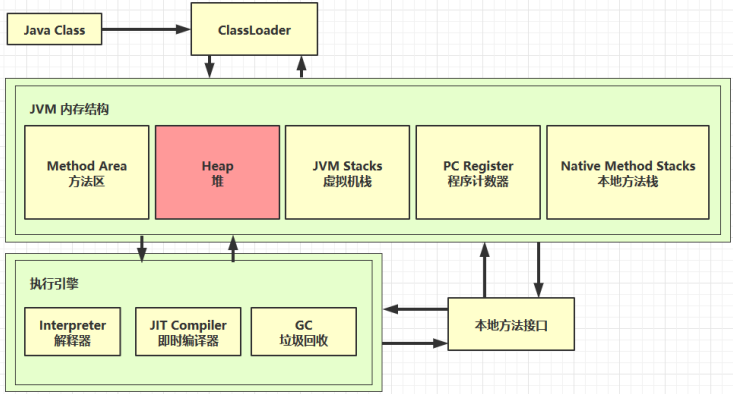
# 4.1 定义
Heap 堆
- 通过 new 关键字,创建对象都会使用堆内存
特点
- 它是线程共享的,堆中对象都需要考虑线程安全的问题
- 有垃圾回收机制
# 4.2 堆内存溢出
当创建的对象足够多并且这些对象都正在被使用,不会被当成垃圾进行处理时,就会产生堆内存溢出的现象
Tip:
- 可以使用
-Xmx来改变堆内存的最大大小- 堆内存溢出的错误信息为:
java.lang.OutOfMemoryError: Java heap space
# 4.3 堆内存诊断
有如下代码进行测试
public class Demo1_4 {
public static void main(String[] args) throws InterruptedException {
System.out.println("1..");
Thread.sleep(30000);
// 分配 10M内存
byte[] bytes = new byte[1024 * 1024 * 10];
System.out.println("2..");
Thread.sleep(30000);
bytes = null;
// 进行一次垃圾回收
System.gc();
System.out.println("3..");
Thread.sleep(1000000L);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
jps 工具:查看当前系统中有哪些 Java 进程
PS JVM> jps 12128 Demo1_4 12116 RemoteMavenServer 14968 7720 Jps 7800 Launcher1
2
3
4
5
6jmap 工具:查看堆内存占用情况
jmap -heap 进程id在输出1时的堆内存情况
Heap Usage: # 堆内存占用情况 PS Young Generation Eden Space: # 新创建对象使用的分区 capacity = 34078720 (32.5MB) # 堆内存容量 used = 4771568 (4.5505218505859375MB) # 堆内存已使用情况 free = 29307152 (27.949478149414062MB) # 可分配 14.001605694110577% used1
2
3
4
5
6
7在输出2时的堆内存情况,因为创建了一个 10M 的字节数组,所以此时堆内存使用量比上次多了 10M 左右的使用
Heap Usage: # 堆内存占用情况 PS Young Generation Eden Space: # 新创建对象使用的分区 capacity = 34078720 (32.5MB) # 堆内存容量 used = 15257344 (14.550537109375MB) # 堆内存已使用情况 free = 18821376 (17.949462890625MB) # 可分配 44.77088341346154% used1
2
3
4
5
6
7在输出3时的堆内存情况,进行了垃圾回收,将分配的 10M 字节数组进行回收,使得堆内存使用量大大减少
Heap Usage: # 堆内存占用情况 PS Young Generation Eden Space: # 新创建对象使用的分区 capacity = 34078720 (32.5MB) # 堆内存容量 used = 681592 (0.6500167846679688MB) # 堆内存已使用情况 free = 33397128 (31.84998321533203MB) # 可分配 2.0000516451322117% used1
2
3
4
5
6
7
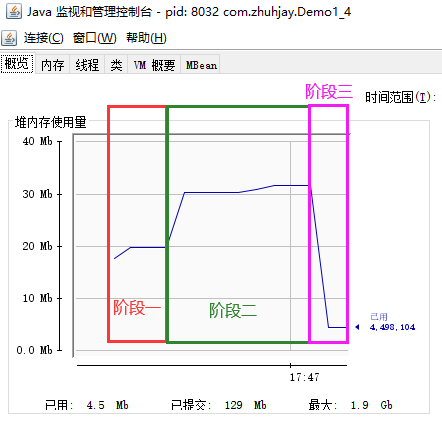
jconsole 工具:图形界面,多功能的监测工具,可以连续监测
分为三个阶段的使用情况,阶段一为初始阶段。阶段二时分配了一段内存,阶段三进行了垃圾回收
jvisualvm 工具:与 jconsole 类似的图形化界面,但是该用具可以 dump堆内存快照,可以查看堆中存活的对象信息
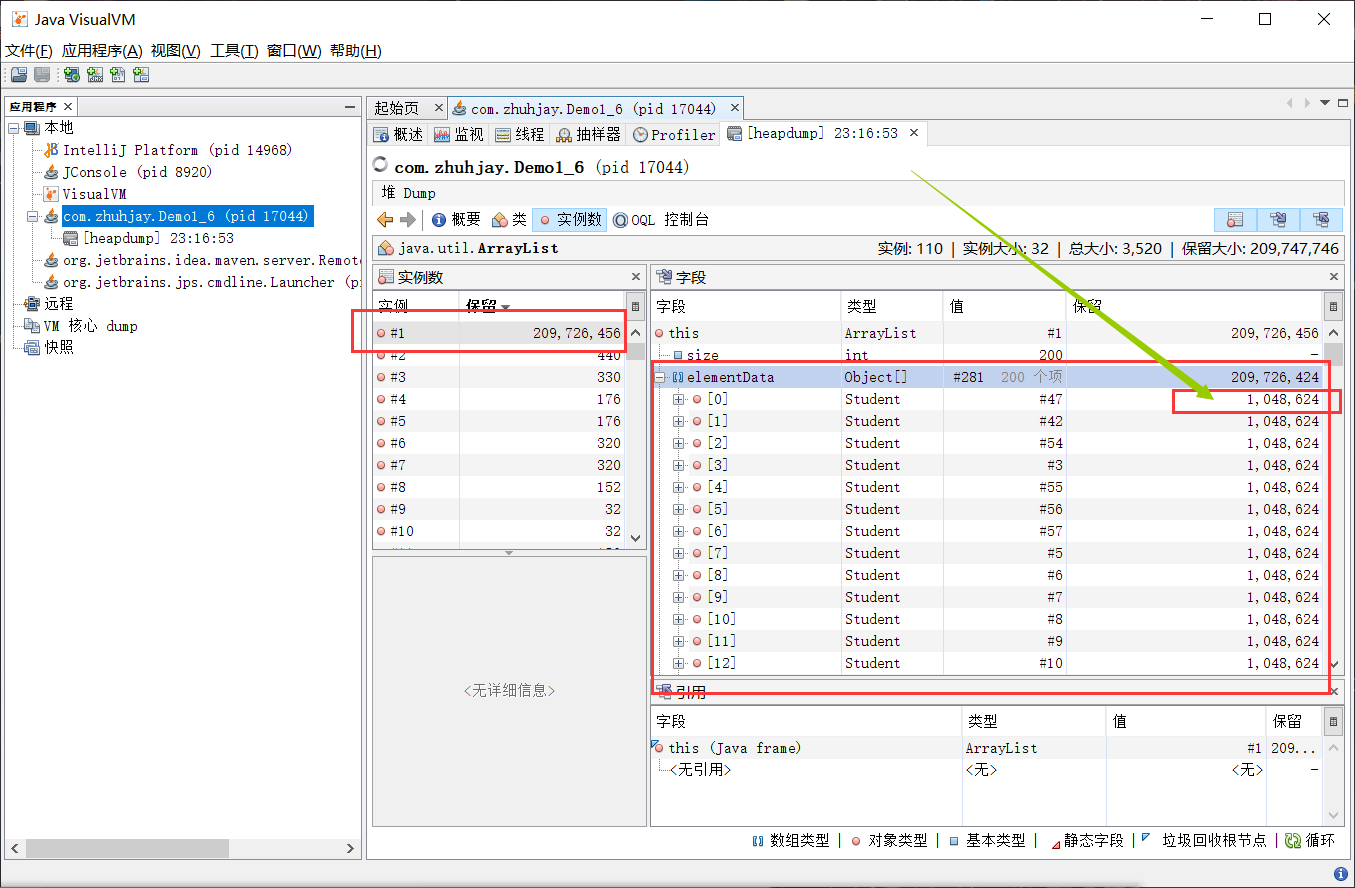
案例/代码:垃圾回收后,内存占用仍然很高
public class Demo1_6 { public static void main(String[] args) throws InterruptedException { List<Student> list = new ArrayList<>(200); for (int i = 0; i < 200; i++) { list.add(new Student()); } // 为了调试而休眠 Thread.sleep(1000000000L); } } class Student { private byte[] big = new byte[1024 * 1024]; }1
2
3
4
5
6
7
8
9
10
11
12
13使用
jps命令获取到该程序的进程id,使用jmap -heap 进程id查看堆内存使用可以发现堆内存总共占用了 (16+187)M,然后使用
jconsole工具进行该进程的 gc 回收Heap Usage: PS Young Generation Eden Space: capacity = 116916224 (111.5MB) used = 17285928 (16.485145568847656MB) free = 99630296 (95.01485443115234MB) 14.784883918249019% used PS Old Generation # 老年代堆内存使用情况 capacity = 334495744 (319.0MB) used = 196736312 (187.62236785888672MB) free = 137759432 (131.37763214111328MB) 58.815789297456654% used1
2
3
4
5
6
7
8
9
10
11
12可以发现,虽然进行了 gc 垃圾回收,但是堆内存占用还是居高不下,使用 jconsole 工具已经没办法进一步查询到具体问题了
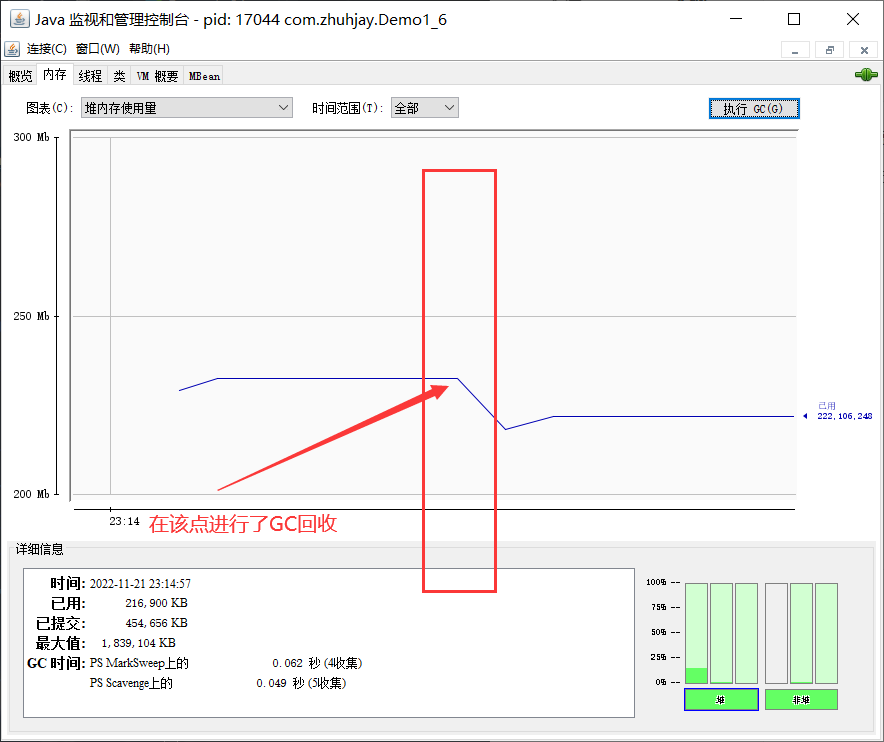
使用 jvisualvm 进行堆内存 dump
使用命令
jvisualvm打开可视化界面,选择当前执行的进程,查看详细信息,然后进行堆内存 dump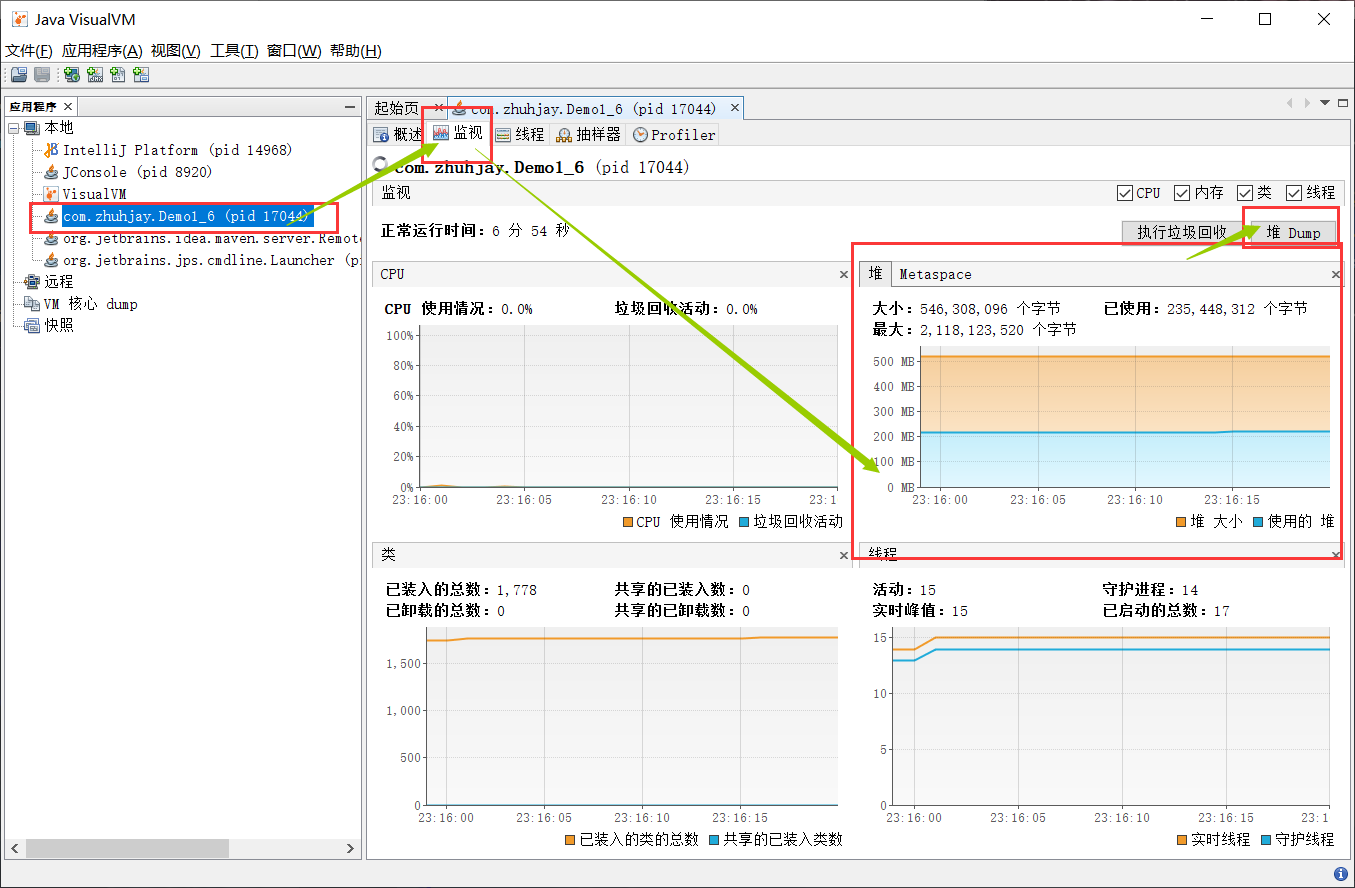
可以发现当前的 ArrayList 对象占用的内存高达约 200M 左右的内存,点击进去查看该对象的详细信息
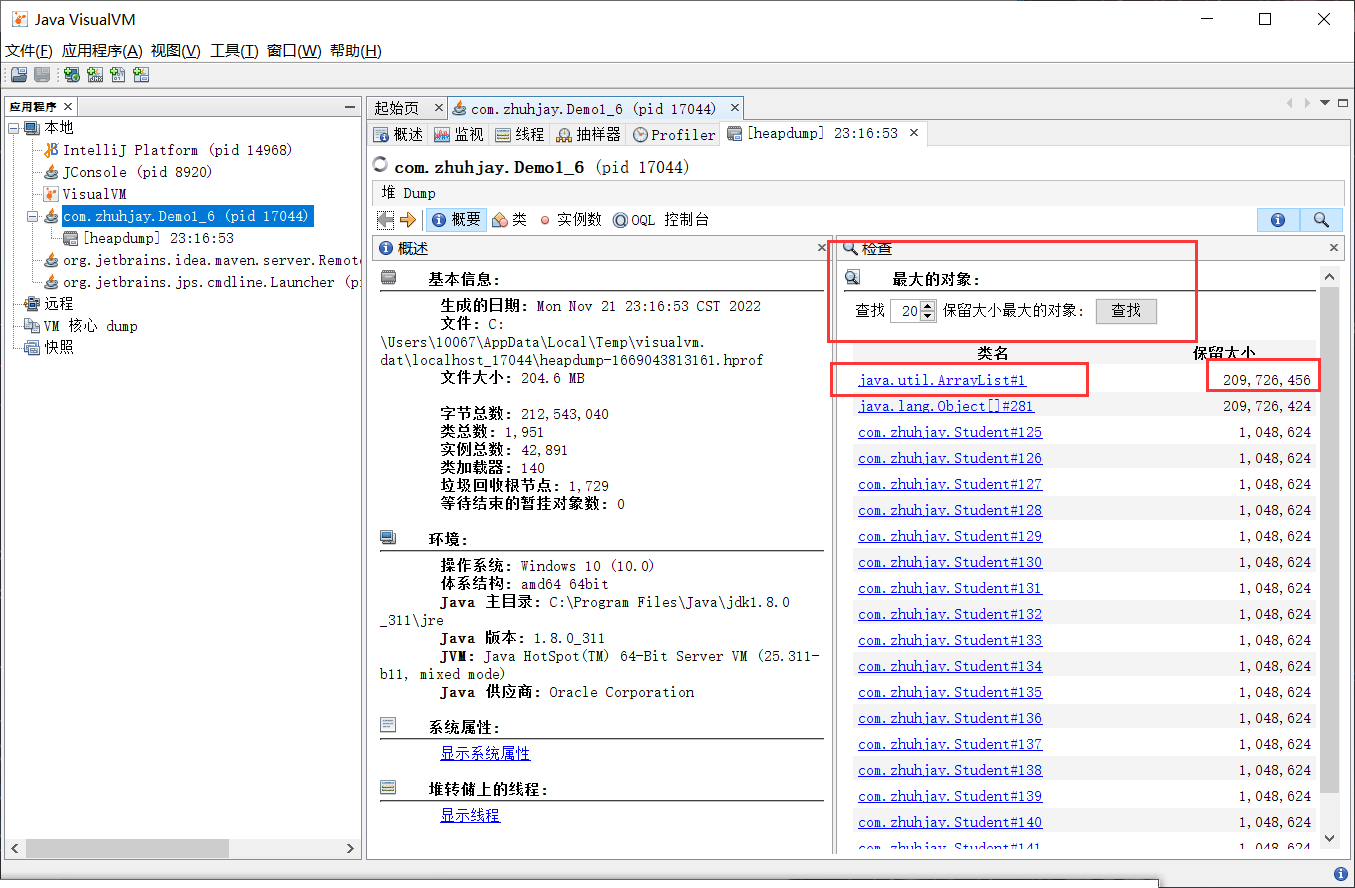
在 ArrayList 对象中的每一个元素都占用了约 1M 的内存大小,一共有200个元素,则总占用就有了大约 200M 的堆内存空间,由此快速定位到代码中存在的问题
# 5 方法区
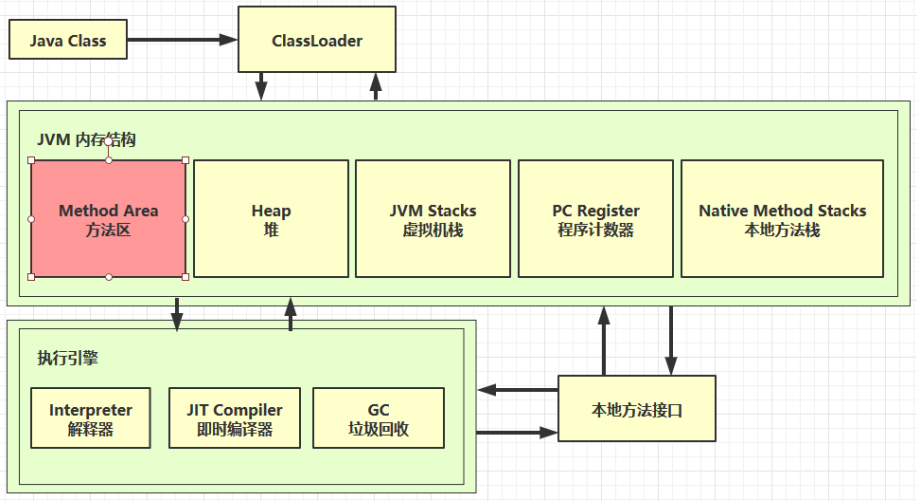
# 5.1 定义
以下是官方对方法区的定义
Java 虚拟机具有 在所有 Java 虚拟机之间共享的方法区域 线程。方法区域类似于已编译的存储区域传统语言的代码或类似于“文本”段的代码 操作系统进程。它存储每个类结构,如运行时常量池、字段和方法数据以及方法和构造函数,包括特殊方法 (§2.9 (opens new window)) 用于类和实例初始化 和接口初始化。
创建方法区域 在虚拟机启动时。虽然方法区域在逻辑上是作为堆的一部分,简单的实现可以选择不垃圾收集或压缩它。这规范不要求方法区域的位置或用于管理已编译代码的策略。方法区域可以是固定大小或可根据计算需要进行扩展,并且可以如果不需要更大的方法区域,则收缩。记忆对于方法区域不需要是连续的。
Java 虚拟机实现可以为程序员或用户控制方法区域的初始大小,以及,对于不同尺寸的方法区域,控制最大值和最小方法区域大小。
以下特殊条件与方法区域相关联:
- 如果方法区域中的内存无法用于满足分配请求,Java 虚拟机抛出一个。
OutOfMemoryError
# 5.2 组成
JDK6 和 JDK8 的内存结构发生了变化
注意:图中的 常量池 指的是 运行时常量池

# 5.3 方法区内存溢出
- JDK1.8 以前会导致永久代内存溢出:
java.lang.OutOfMemoryError: PermGen space - JDK1.8 以后会导致元空间内存溢出:
java.lang.OutOfMemoryError: Metaspace
演示 JDK1.8 以后元空间内存溢出(JDK1.6 代码几乎相同,永久代使用 -XX:MaxPermSize=8m)
public class Demo1_7 extends ClassLoader {
public static void main(String[] args) {
int j = 0;
try {
Demo1_7 test = new Demo1_7();
for (int i = 0; i < 10000; i++, j++) {
// ClassWriter 作用是生成类的二进制字节码
ClassWriter cw = new ClassWriter(0);
// 版本号,public,类名,包名,父类,接口
cw.visit(Opcodes.V1_8, Opcodes.ACC_PUBLIC, "Class" + i, null, "java/lang/Object", null);
// 返回byte信息
byte[] code = cw.toByteArray();
// 执行类的加载
test.defineClass("Class" + i, code, 0, code.length);
}
} finally {
System.out.println(j);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
在 1.8 以后元空间使用的是系统没存,没有限制大小,不会发生溢出的情况,需要设置 -XX:MaxMetaspaceSize=8m
5411
Exception in thread "main" java.lang.OutOfMemoryError: Metaspace
at java.lang.ClassLoader.defineClass1(Native Method)
at java.lang.ClassLoader.defineClass(ClassLoader.java:763)
at java.lang.ClassLoader.defineClass(ClassLoader.java:642)
at com.zhuhjay.Demo1_7.main(Demo1_7.java:23)
2
3
4
5
6
方法区内存溢出场景:
- Spring
- Mybatis
这些场景都会使用 CGLIB 等代理技术动态的生成字节码,使用不当可能会导致方法区内存溢出的情况。
# 5.4 运行时常量池
- 常量池,就是一张表,虚拟机指令根据这张常量表找到要执行的类名、方法名、参数类型、字面量等信息
- 运行时常量池,常量池是 *.class 文件中的,当该类被加载,它的常量池信息就会放入运行时常量池,并把里面的符号地址变为真实地址
Tip: 常量池的概念解析
编译运行以下代码
public class Demo1_8 { public static void main(String[] args) { System.out.println("hello world"); } }1
2
3
4
5将编译后的 class 文件进行反编译
javap -v Demo1_8.class
- 源码 1-8 行是文件的 类的基本信息
- 源码 9-42 行是 常量池信息
- 源码 44-72 行是 类方法定义信息
- 当 class 文件被运行之后,所有的
#..都会被赋予真实的物理地址信息Classfile /G:/Idea_workspace/JVM/target/classes/com/zhuhjay/Demo1_8.class Last modified 2022-11-22; size 548 bytes MD5 checksum 551e83a2ede53badac918978a8846964 Compiled from "Demo1_8.java" public class com.zhuhjay.Demo1_8 minor version: 0 major version: 52 flags: ACC_PUBLIC, ACC_SUPER Constant pool: #1 = Methodref #6.#20 // java/lang/Object."<init>":()V #2 = Fieldref #21.#22 // java/lang/System.out:Ljava/io/PrintStream; #3 = String #23 // hello world #4 = Methodref #24.#25 // java/io/PrintStream.println:(Ljava/lang/String;)V #5 = Class #26 // com/zhuhjay/Demo1_8 #6 = Class #27 // java/lang/Object #7 = Utf8 <init> #8 = Utf8 ()V #9 = Utf8 Code #10 = Utf8 LineNumberTable #11 = Utf8 LocalVariableTable #12 = Utf8 this #13 = Utf8 Lcom/zhuhjay/Demo1_8; #14 = Utf8 main #15 = Utf8 ([Ljava/lang/String;)V #16 = Utf8 args #17 = Utf8 [Ljava/lang/String; #18 = Utf8 SourceFile #19 = Utf8 Demo1_8.java #20 = NameAndType #7:#8 // "<init>":()V #21 = Class #28 // java/lang/System #22 = NameAndType #29:#30 // out:Ljava/io/PrintStream; #23 = Utf8 hello world #24 = Class #31 // java/io/PrintStream #25 = NameAndType #32:#33 // println:(Ljava/lang/String;)V #26 = Utf8 com/zhuhjay/Demo1_8 #27 = Utf8 java/lang/Object #28 = Utf8 java/lang/System #29 = Utf8 out #30 = Utf8 Ljava/io/PrintStream; #31 = Utf8 java/io/PrintStream #32 = Utf8 println #33 = Utf8 (Ljava/lang/String;)V { public com.zhuhjay.Demo1_8(); descriptor: ()V flags: ACC_PUBLIC Code: stack=1, locals=1, args_size=1 0: aload_0 1: invokespecial #1 // Method java/lang/Object."<init>":()V 4: return LineNumberTable: line 7: 0 LocalVariableTable: Start Length Slot Name Signature 0 5 0 this Lcom/zhuhjay/Demo1_8; public static void main(java.lang.String[]); descriptor: ([Ljava/lang/String;)V flags: ACC_PUBLIC, ACC_STATIC Code: stack=2, locals=1, args_size=1 0: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream; 3: ldc #3 // String hello world 5: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V 8: return LineNumberTable: line 9: 0 line 10: 8 LocalVariableTable: Start Length Slot Name Signature 0 9 0 args [Ljava/lang/String; } SourceFile: "Demo1_8.java"1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74进行main方法信息进行分析 62-66 行代码截取,在CPU中是不会读取到
//后面的注释信息的,这些注释信息是为了让程序员快速明白的注释信息。stack=2, locals=1, args_size=1 0: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream; 3: ldc #3 // String hello world 5: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V 8: return1
2
3
4
5
0: getstatic #2
getstatic:获取类的成员变量
#2:去常量池
Constant pool中查找对应的信息
#2 = Fieldref #21.#22:需要找到地址#21.#22,该组成为 成员变量的引用
#21 = Class #28:需要找到地址#28,该地址信息为 Class
#28 = Utf8 java/lang/System:找到System类名
#22 = NameAndType #29:#30:需要找到 方法名和其类型
#29 = Utf8 out:找到调用的静态方法
#30 = Utf8 Ljava/io/PrintStream;:找到类型即该条命令就是为了找到该结果
Field java/lang/System.out:Ljava/io/PrintStream;,这也就是源码的System.out
3: ldc #3
- ldc:找到一个地址,并作为下一次指令的参数
- #3:
#3 = String #23:需要找到地址#23#23 = Utf8 hello world:找到类型为Utf8的字符串- 即该条指令就是为了找到结果
hello world
5: invokevirtual #4
- invokevirtual:执行一次虚方法调用(方法调用)
- #4:
#4 = Methodref #24.#25:需要找到地址#24.#25,该组为 方法引用#24 = Class #31:需要找到地址#31,是一个 Class 对象#31 = Utf8 java/io/PrintStream:一个输出流的类名#25 = NameAndType #32:#33:需要找到地址#32:#33,方法名及其类型#32 = Utf8 println:找到需要调用的方法名称#33 = Utf8 (Ljava/lang/String;)V:参数类型为 String,无返回值- 即该条指令就是为了找到结果
Method java/io/PrintStream.println:(Ljava/lang/String;)V,也就是源码中的println("hello world"),需要将上一个指令的数据作为方法参数
# 5.5 StringTable
用来存储字符串的常量池,使用硬编码的字符串都会被存储到字符串常量池中
eg:
new String("a")会被放入字符串常量池和堆中,返回值是堆中的引用"a"会被直接放到字符串常量池中,返回值是串池中的引用
# 5.5.1 解析引入
现有以下代码,将其进行编译后,使用
javap对其进行反编译,查看常量池的信息public class Demo1_9 { public static void main(String[] args) { String s1 = "a"; String s2 = "b"; String s3 = "ab"; } }1
2
3
4
5
6
7编译结果如下(只展示部分)
- 常量池中的信息,都会被加载到运行时常量池中,这时 a b ab 都是常量池中的符号,还没有变为 java 字符串对象
ldc #2会把 a 符号变为 "a" 字符串对象,然后到 StringTable 中去找是否存在该值,不存在则存入 StringTable 中- StringTable 是 hashtable 结构,不能扩容,一创建就固定了大小
ldc #3ldc #4同上astore_1即是将上一条指令的内容存入到方法栈桢的变量表的 1 位置上
Constant pool: #2 = String #25 // a #3 = String #26 // b #4 = String #27 // ab public static void main(java.lang.String[]); Code: stack=1, locals=4, args_size=1 0: ldc #2 // String a 2: astore_1 3: ldc #3 // String b 5: astore_2 6: ldc #4 // String ab 8: astore_3 9: return LocalVariableTable: # main方法栈帧的变量表 Start Length Slot Name Signature 0 10 0 args [Ljava/lang/String; 3 7 1 s1 Ljava/lang/String; 6 4 2 s2 Ljava/lang/String; 9 1 3 s3 Ljava/lang/String;1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 5.5.2 变量拼接
现对源代码进行改变如下,需要了解字符串变量拼接的原理,以及
s3 == s4是否成立public class Demo1_9 { public static void main(String[] args) { String s1 = "a"; String s2 = "b"; String s3 = "ab"; String s4 = s1 + s2; } }1
2
3
4
5
6
7
8进行反编译(只展示部分),根据如下执行的指令,可以发现
String s4 = s1 + s2;是通过new StringBuilder().append("a").append("b").toString()来进行组成的字符串- StringBuilder 中的 toString 方法就是通过
new String("ab")在堆空间中创建一个对象 - 以上即可得出
s3 == s4不成立,s3 变量指向串池,s4 变量指向堆中的对象
Constant pool: #2 = String #30 // a #3 = String #31 // b #4 = String #32 // ab #5 = Class #33 // java/lang/StringBuilder #6 = Methodref #5.#29 // java/lang/StringBuilder."<init>":()V #7 = Methodref #5.#34 // java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder; #8 = Methodref #5.#35 // java/lang/StringBuilder.toString:()Ljava/lang/String; public static void main(java.lang.String[]); 0: ldc #2 // String a 2: astore_1 3: ldc #3 // String b 5: astore_2 6: ldc #4 // String ab 8: astore_3 9: new #5 // class java/lang/StringBuilder 12: dup 13: invokespecial #6 // Method java/lang/StringBuilder."<init>":()V 16: aload_1 17: invokevirtual #7 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder; 20: aload_2 21: invokevirtual #7 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder; 24: invokevirtual #8 // Method java/lang/StringBuilder.toString:()Ljava/lang/String; 27: astore 4 29: return1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 5.5.3 常量拼接
现对源代码进行改变如下,需要了解字符串常量拼接的原理,以及
s3 == s5是否成立public class Demo1_9 { public static void main(String[] args) { String s1 = "a"; String s2 = "b"; String s3 = "ab"; String s4 = s1 + s2; String s5 = "a" + "b"; } }1
2
3
4
5
6
7
8
9进行反编译(只展示部分),根据如下执行的指令,可以发现
String s5 = "a" + "b";直接往 StringTable 串池中查找 "ab"- 发生以上的原因:javac 在编译期间的优化,结果已经在编译器确定为 "ab"
- 即得出
s3 == s5成立,s3 和 s5 都是来自串池中的 "ab",属于同一个对象
public static void main(java.lang.String[]); 0: ldc #2 // String a 2: astore_1 3: ldc #3 // String b 5: astore_2 6: ldc #4 // String ab 8: astore_3 9: new #5 // class java/lang/StringBuilder 12: dup 13: invokespecial #6 // Method java/lang/StringBuilder."<init>":()V 16: aload_1 17: invokevirtual #7 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder; 20: aload_2 21: invokevirtual #7 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder; 24: invokevirtual #8 // Method java/lang/StringBuilder.toString:()Ljava/lang/String; 27: astore 4 29: ldc #4 // String ab 31: astore 5 33: return1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 5.5.4 intern (JDK1.8)
现对源代码进行改变如下,需要了解 String.intern() 方法的原理,以及
s6 == s7是否成立public class Demo1_9 { public static void main(String[] args) { String s6 = new String("c") + new String("d"); String s7 = "cd"; String intern = s6.intern(); } }1
2
3
4
5
6
7进行反编译(只展示部分),根据如下执行的指令,可以发现
- 通过
new String("c")方法,会在堆内存和常量池中各创建一份数据,然后通过 变量拼接 的方式在堆内存中生成一份cd,但此数据没有入串池中 String s7 = "cd";此时串池中没有存在该数据,所以入串池操作s6.intern();将该字符串对象尝试放入串池,如果有则不会放入,如果没有则放入串池,会把串池中的对象返回- 程序执行完后,会发现 s6 属于堆内存中的对象,而 s7 属于串池中的对象,所以
s6 == s7不成立
public static void main(java.lang.String[]); 0: new #2 // class java/lang/StringBuilder 3: dup 4: invokespecial #3 // Method java/lang/StringBuilder."<init>":()V 7: new #4 // class java/lang/String 10: dup 11: ldc #5 // String c 13: invokespecial #6 // Method java/lang/String."<init>":(Ljava/lang/String;)V 16: invokevirtual #7 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder; 19: new #4 // class java/lang/String 22: dup 23: ldc #8 // String d 25: invokespecial #6 // Method java/lang/String."<init>":(Ljava/lang/String;)V 28: invokevirtual #7 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder; 31: invokevirtual #9 // Method java/lang/StringBuilder.toString:()Ljava/lang/String; 34: astore_1 35: ldc #10 // String cd 37: astore_2 38: aload_1 39: invokevirtual #11 // Method java/lang/String.intern:()Ljava/lang/String; 42: astore_3 43: return1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22- 通过
思考:
将以上代码修改为以下代码,
s6 == s7又会是怎样的结果?public class Demo1_9 { public static void main(String[] args) { String s6 = new String("c") + new String("d"); String intern = s6.intern(); String s7 = "cd"; } }1
2
3
4
5
6
7分析:
- 执行完 s6 变量赋值过后,常量池和堆的数据如下
- StringTable ["c", "d"]
- Heap ['new String("c")', 'new String("d")', 'new String("cd")']
- 执行完 s6.intern 后,会判断常量池中是否存在 "cd"
- StringTable ["c", "d", "cd"] (实际上这里的 "cd" 是堆中 'new String("cd")' 的一个引用,是用一个对象)
- Heap ['new String("c")', 'new String("d")', 'new String("cd")']
- 执行到 s7 时,发现常量池中存在了 "cd",所以直接引用
综上所述,当前情况下的
s6 == s7是成立的
# 5.5.5 intern (JDK1.6)
在 JDK1.6 中,以下执行的结果与 JDK1.8 的相同: s6 == s7 不成立
public class Demo1_9 {
public static void main(String[] args) {
String s6 = new String("c") + new String("d");
String s7 = "cd";
String intern = s6.intern();
}
}
2
3
4
5
6
7
但是当改为以下代码时,结果却不尽相同
- 执行完 s6 变量赋值过后,常量池和堆的数据如下
- StringTable ["c", "d"]
- Heap ['new String("c")', 'new String("d")', 'new String("cd")']
- 执行完 s6.intern 后,会判断常量池中是否存在 "cd",如果不存在,那么将 s6 拷贝一份放入常量池中,并返回
- StringTable ["c", "d", "cd"] (在此时,"cd" 和 'new String("cd")' 不是同一个对象,因为是通过拷贝的方式)
- Heap ['new String("c")', 'new String("d")', 'new String("cd")']
- 执行到 s7 时,发现常量池中存在了 "cd",所以直接引用
综上所述,当前情况下的 s6 == s7 是不成立的
public class Demo1_9 {
public static void main(String[] args) {
String s6 = new String("c") + new String("d");
String intern = s6.intern();
String s7 = "cd";
}
}
2
3
4
5
6
7
# 5.5.6 特性总结
常量池中的字符串仅是符号,第一次用到时才变为对象
利用串池的机制,来避免重复创建字符串对象
字符串变量拼接的原理是 StringBuilder(1.8)
字符串常量拼接的原理是编译期优化
可以使用 intern 方法,主动将串池中还没有的字符串对象放入串池
- 1.8 将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有则放入串池, 会把串池中的对象返回
- 1.6 将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有会把此对象复制一份,放入串池,会把串池中的对象返回
# 5.6 StringTable 面试题
学习完 StringTable 字符串常量池后,能正确的理解回答下面的题目,那么恭喜你掌握了一个新的知识!
String s1 = "a";
String s2 = "b";
String s3 = "a" + "b";
String s4 = s1 + s2;
String s5 = "ab";
String s6 = s4.intern();
// 问
System.out.println(s3 == s4);
System.out.println(s3 == s5);
System.out.println(s3 == s6);
String x2 = new String("c") + new String("d");
String x1 = "cd";
x2.intern();
// 问,如果调换了【最后两行代码】的位置呢?如果是jdk1.6呢?
System.out.println(x1 == x2);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
答案:
false true true
jdk1.8: false true
jdk1.6: false false
2
3
# 5.7 StringTable 位置
在 JDK1.6 时,StringTable 是常量池的一部分,常量池存储在永久代中(在永久代中需要进行 Full GC 才会进行垃圾回收,回收效率低)
在 JDK1.8 时,StringTable 是堆中的一部分,垃圾回收跟随堆进行,回收效率高
怎么证明以上两个版本存储的位置不相同?
- 在 JDK1.6 中,如果常量池中发生了内存溢出,那么就会报错
java.lang.OutOfMemoryError: PermGen space,永久代内存溢出 - 在 JDK1.8 中,如果常量池中发生了内存溢出,那么就会报错
java.lang.OutOfMemoryError: Java heap space,堆内存溢出
通过以上思路,来证明 JDK1.6 和 JDK1.8 StringTable 常量池的位置不同
案例代码
public class Demo1_10 {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
int i = 0;
try {
for (int j = 0; j < 260000; j++) {
list.add(String.valueOf(j).intern());
i++;
}
} catch (Throwable e) {
e.printStackTrace();
} finally {
System.out.println(i);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
JDK1.8 验证:需要设置堆内存的大小 -Xmx10m,会发现有以下结果,报错信息和预想的结果不一样?
- 原来,在 JVM规范中 当GC垃圾回收花了 98% 的时间只释放了 2% 的堆空间时,JVM 就会认为该程序没救了,就直接抛出该异常
- 那么要跳过这个限制,需要再多配置一个参数
-XX:-UseGCOverheadLimit
java.lang.OutOfMemoryError: GC overhead limit exceeded
at java.lang.Integer.toString(Integer.java:403)
at java.lang.String.valueOf(String.java:3099)
at com.zhuhjay.Demo1_10.main(Demo1_10.java:16)
145367
2
3
4
5
最终结果就是预想的结果了!
*** java.lang.instrument ASSERTION FAILED ***: "!errorOutstanding" with message can't create byte arrau at JPLISAgent.c line: 813
java.lang.OutOfMemoryError: Java heap space
at java.lang.Integer.toString(Integer.java:401)
at java.lang.String.valueOf(String.java:3099)
at com.zhuhjay.Demo1_10.main(Demo1_10.java:16)
146837
2
3
4
5
6
JDK1.6 验证:需要设置永久代内存的大小 -XX:MaxPermSize=10m
# 5.8 StringTable 垃圾回收
查看字符串常量池 StringTable 的垃圾回收是否会在空间不足时进行字符串常量池的垃圾回收
示例代码,为了更进一步查看堆内存和字符串常量池的空间,需要添加以下参数
-Xmx10m:设置堆的大小,为了方便测试GC垃圾回收-XX:+PrintStringTableStatistics:打印字符串表的信息-XX:+PrintGCDetails -verbose:gc:统计垃圾回收的信息
public class Demo1_11 {
public static void main(String[] args) {
int i = 0;
try {
// TODO 待插入代码
} catch (Throwable e) {
e.printStackTrace();
} finally {
System.out.println(i);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
查看输出结果,认识一下下面所代表的含义
Heap # 堆内存的占用情况
PSYoungGen total 2560K, used 1676K [0x00000000ffd00000, 0x0000000100000000, 0x0000000100000000)
eden space 2048K, 81% used [0x00000000ffd00000,0x00000000ffea3198,0x00000000fff00000)
from space 512K, 0% used [0x00000000fff80000,0x00000000fff80000,0x0000000100000000)
to space 512K, 0% used [0x00000000fff00000,0x00000000fff00000,0x00000000fff80000)
ParOldGen total 7168K, used 0K [0x00000000ff600000, 0x00000000ffd00000, 0x00000000ffd00000)
object space 7168K, 0% used [0x00000000ff600000,0x00000000ff600000,0x00000000ffd00000)
Metaspace used 3167K, capacity 4496K, committed 4864K, reserved 1056768K
class space used 345K, capacity 388K, committed 512K, reserved 1048576K
SymbolTable statistics: # 符号表的详细信息(也是常量池的一部分,但是并不关心这部分内容)
Number of buckets : 20011 = 160088 bytes, avg 8.000
Number of entries : 13260 = 318240 bytes, avg 24.000
Number of literals : 13260 = 568232 bytes, avg 42.853
Total footprint : = 1046560 bytes
Average bucket size : 0.663
Variance of bucket size : 0.666
Std. dev. of bucket size: 0.816
Maximum bucket size : 6
StringTable statistics: # StringTable 统计信息,使用 hashtable 结构
Number of buckets : 60013 = 480104 bytes, avg 8.000 # 桶个数 = 字节数
Number of entries : 1739 = 41736 bytes, avg 24.000 # 键值对个数 = 字节数
Number of literals : 1739 = 156592 bytes, avg 90.047 # 字符串常量个数 = 字节数
Total footprint : = 678432 bytes # 总的空间
Average bucket size : 0.029
Variance of bucket size : 0.029
Std. dev. of bucket size: 0.171
Maximum bucket size : 3
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
现在在以上代码中插入以下代码:将10000个字符串添加到字符串常量池中,此时字符串常量池中理应会在原来的 1739 基础上多 10000
for (int j = 0; j < 10000; j++) {
String.valueOf(j).intern();
i++;
}
2
3
4
可以看到此时运行就有了 GC垃圾回收 的信息,此时字符串常量池没有达到预期的效果,说明当常量池中有不被使用的数据会被垃圾回收
[GC (Allocation Failure) [PSYoungGen: 2048K->488K(2560K)] 2048K->704K(9728K), 0.0031150 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
10000
Heap
...省略展示
SymbolTable statistics:
...省略展示
StringTable statistics:
Number of buckets : 60013 = 480104 bytes, avg 8.000
Number of entries : 4026 = 96624 bytes, avg 24.000
Number of literals : 4026 = 266888 bytes, avg 66.291
Total footprint : = 843616 bytes
Average bucket size : 0.067
Variance of bucket size : 0.065
Std. dev. of bucket size: 0.256
Maximum bucket size : 3
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 5.9 StringTable 性能调优
字符串常量池的性能随着分配桶的个数越多,效率越高,参数配置
-XX:StringTableSize=1009,配置最小值为 1009String.intern 调优了一大部分性能,防止滋生很多的重复数据
# 6 直接内存
直接内存是系统内存
# 6.1 定义
Direct Memory
- 常见于 NIO 操作时,用于数据缓冲区
- 分配回收成本较高,但读写性能高
- 不受 JVM 内存回收管理
# 6.2 使用直接内存
# 6.2.1 测试IO与Direct Memory读写效率
使用差不多 1G 的文件来进行读写对比
public class Demo1_12 {
private static final String FROM = "G:\\maven\\maven_repository_0.zip";
private static final String TO = "G:\\IDM_DownLoad\\Video\\Temp\\maven.zip";
private static final int _1MB = 1024 * 1024;
public static void main(String[] args) {
io();
directBuffer();
}
private static void directBuffer() {
long start = System.nanoTime();
try (FileChannel from = new FileInputStream(FROM).getChannel();
FileChannel to = new FileOutputStream(TO).getChannel();
) {
ByteBuffer bb = ByteBuffer.allocateDirect(_1MB);
while (true) {
int length = from.read(bb);
if (length == -1) {
break;
}
bb.flip();
to.write(bb);
bb.clear();
}
} catch (Exception e) {
e.printStackTrace();
}
long end = System.nanoTime();
System.out.println("directBuffer 用时:" + (end - start) / 1000_000.0);
}
private static void io() {
long start = System.nanoTime();
try (FileInputStream from = new FileInputStream(FROM);
FileOutputStream to = new FileOutputStream(TO);
) {
byte[] buf = new byte[_1MB];
while (true) {
int length = from.read(buf);
if (length == -1) {
break;
}
to.write(buf, 0, length);
}
} catch (Exception e) {
e.printStackTrace();
}
long end = System.nanoTime();
System.out.println("io 用时:" + (end - start) / 1000_000.0);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
对比结果如下,单位ms,可以发现使用直接内存读写效率更高
io 用时:19611.177
directBuffer 用时:5490.16
2

- Java的 io 操作涉及到 CPU 的用户态和内核态
- io 操作需要操作系统从磁盘中进行磁盘文件的读取,将磁盘文件读取到系统内存中的系统缓存区
- 此时 Java 不能直接操作该缓存区,需要在 Java 堆内存中开辟一块 java缓冲区byte[]
- 然后将 系统缓冲区 的数据写到 Java缓冲区 中才能进一步操作
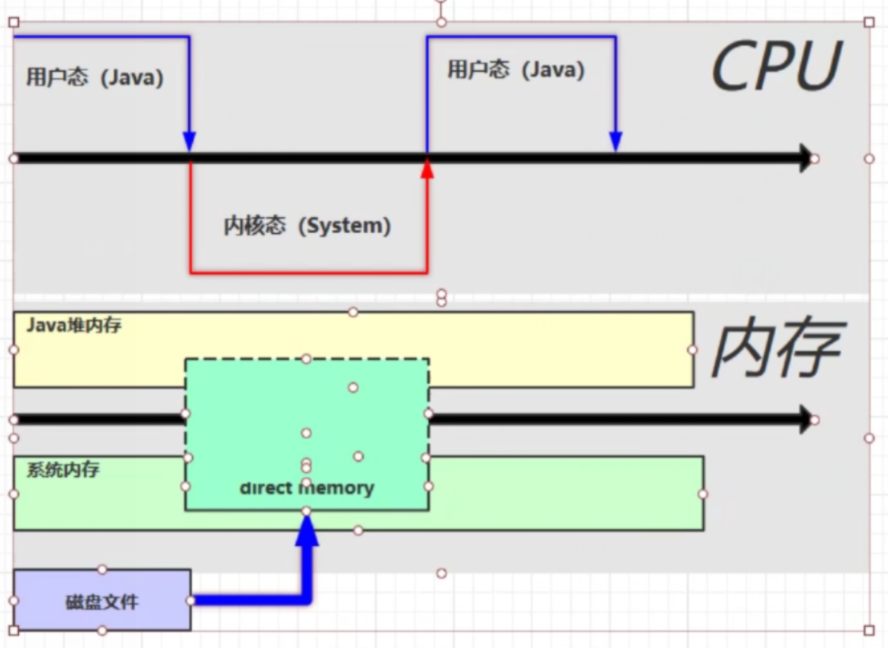
- 调用
ByteBuffer bb = ByteBuffer.allocateDirect(_1MB);时,会在 系统内存 和 Java堆内存 中开辟一块direct Memory内存来进行使用,这就是直接内存,使得 Java 可以直接操作
# 6.2.2 直接内存溢出
每次分配 100M 内存,直到 Direct buffer memory 溢出
public class Demo1_13 {
private static final int _100MB = 1024 * 1024 * 100;
public static void main(String[] args) {
List<ByteBuffer> list = new ArrayList<>();
int i = 0;
try {
while (true) {
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(_100MB);
list.add(byteBuffer);
i++;
}
} finally {
System.out.println(i);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
可以看到直接内存分配到大约 1.7G 时就溢出了
17
Exception in thread "main" java.lang.OutOfMemoryError: Direct buffer memory
at java.nio.Bits.reserveMemory(Bits.java:695)
at java.nio.DirectByteBuffer.<init>(DirectByteBuffer.java:123)
at java.nio.ByteBuffer.allocateDirect(ByteBuffer.java:311)
at com.zhuhjay.Demo1_13.main(Demo1_13.java:19)
2
3
4
5
6
# 6.2.3 直接内存释放
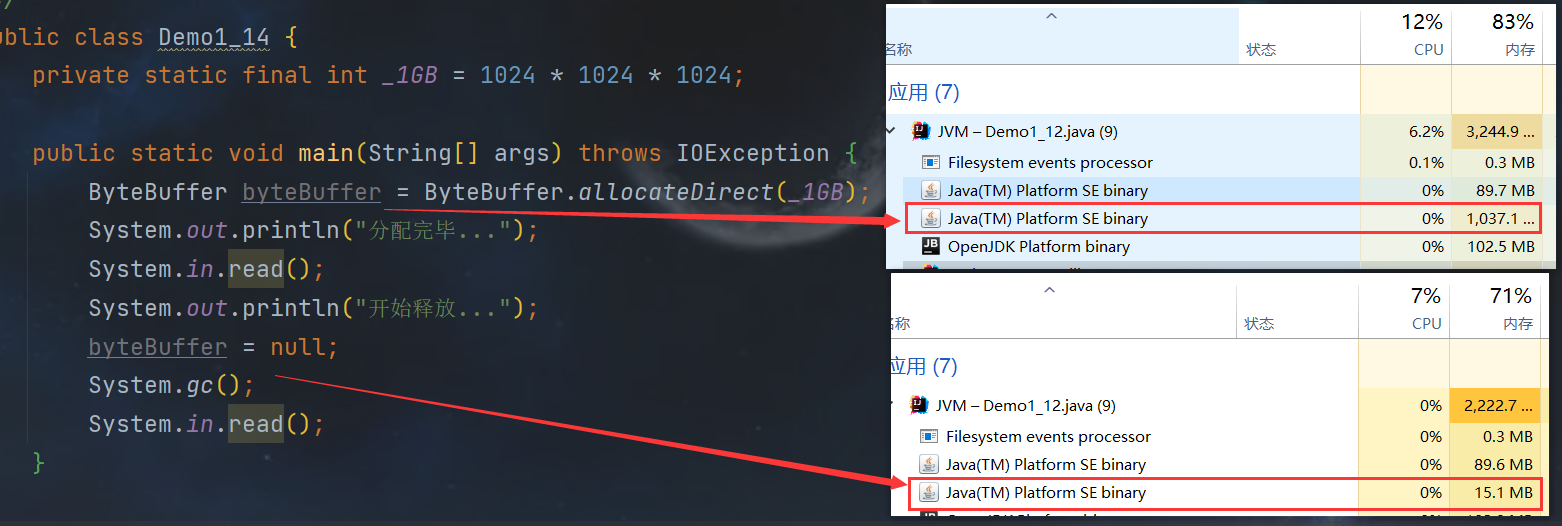
查看以下案例,分配 1GB 的内存,然后使用 GC 进行回收
public class Demo1_14 {
private static final int _1GB = 1024 * 1024 * 1024;
public static void main(String[] args) throws IOException {
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(_1GB);
System.out.println("分配完毕...");
System.in.read();
System.out.println("开始释放...");
byteBuffer = null;
System.gc();
System.in.read();
}
}
2
3
4
5
6
7
8
9
10
11
12
结果如图所示,这样一来感觉好像可以被 GC垃圾回收 进行 直接内存 的回收,但其实并不然。
接下来 Unsafe 脱离 JVM 的内存管理来进行 直接内存 分配
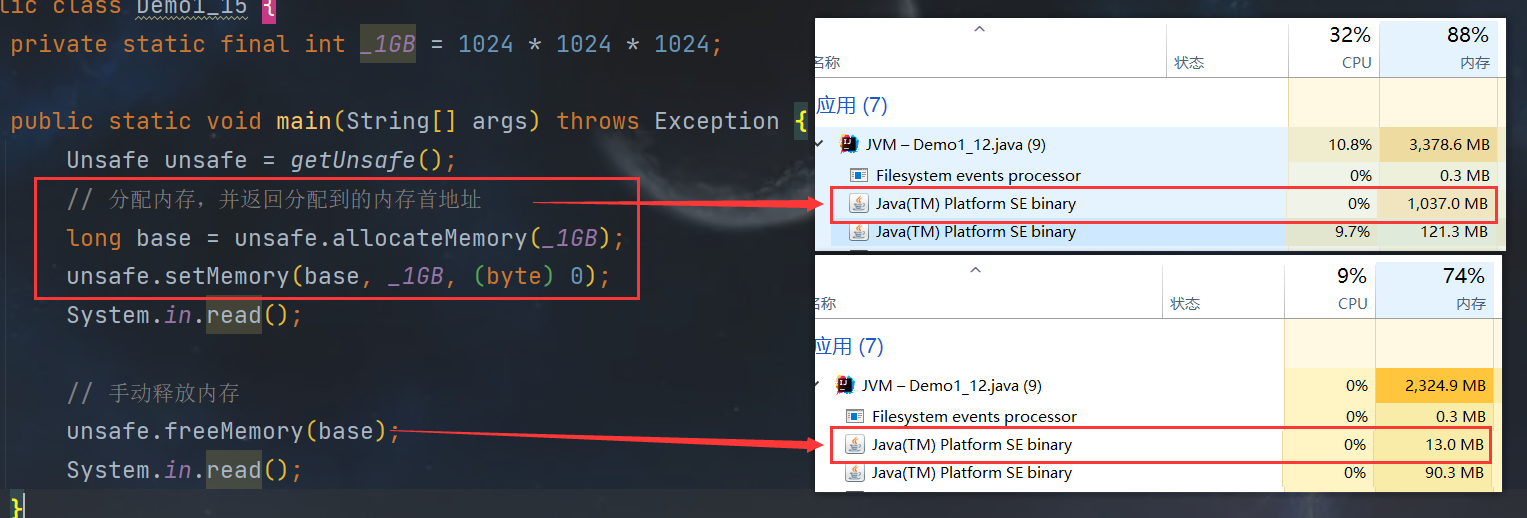
public class Demo1_15 {
private static final int _1GB = 1024 * 1024 * 1024;
public static void main(String[] args) throws Exception {
Unsafe unsafe = getUnsafe();
// 分配内存,并返回分配到的内存首地址
long base = unsafe.allocateMemory(_1GB);
unsafe.setMemory(base, _1GB, (byte) 0);
System.in.read();
// 手动释放内存
unsafe.freeMemory(base);
System.in.read();
}
private static Unsafe getUnsafe() throws Exception {
Field field = Unsafe.class.getDeclaredField("theUnsafe");
field.setAccessible(true);
return (Unsafe) field.get(null);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
可以发现使用 直接内存 是通过 Unsafe 进行管理的,GC垃圾回收 只能对 JVM内存有效
查看 ByteBuffer.allocateDirect() 方法的源码
- 使用了 Unsafe 进行 直接内存的分配
- 使用了
Cleaner特殊对象,虚引用PhantomReference<Object>对象 - 虚引用对象
Cleaner所关联的实际对象ByteBuffer被 GC垃圾回收之后,就会主动调用回调对象Deallocator主动的释放 直接内存
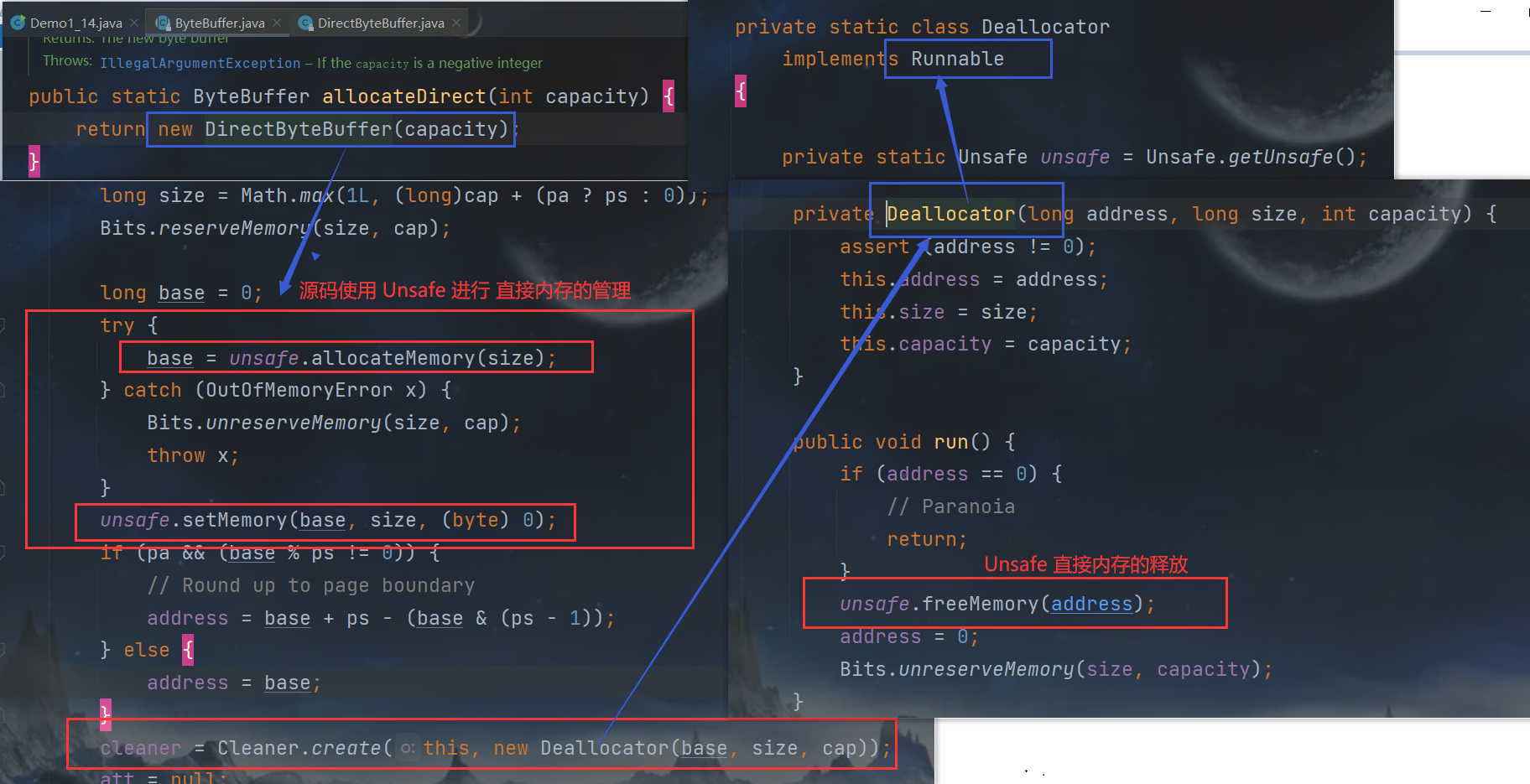
# 6.3 分配和回收原理
- 使用了 Unsafe 对象完成直接内存的分配回收,并且回收需要主动调用 freeMemory 方法
- ByteBuffer 的实现类内部,使用了 Cleaner(虚引用)来监测 ByteBuffer 对象,一旦 ByteBuffer 对象被垃圾回收,那么就会由 ReferenceHandler 线程通过 Cleaner 的 clean 方法调 用 freeMemory 来释放直接内存
禁用显示回收对直接内存的影响(就是禁用代码层面的 System.gc(),使其无效)
System.gc()触发的是Full GC,比较影响性能的,不光回收新生代,还会回收老年代,会使得程序暂停时间较长- 使用虚拟机参数
-XX:+DisableExplicitGC - 代码层面的 GC 失效后,
ByteBuffer得不到内存的释放,使得 直接内存 也无法被释放,需要等到下一次 GC 时才会触发 - 问题解决:手动调用 Unsafe 释放直接内存
